深入理解Transformer结构在大模型中的应用
本文将探讨大模型的Transformer架构,揭示其在人工智能领域的核心作用和未来发展趋势。
1. 大模型的基本概念
大模型,或称为大型神经网络模型,是指那些拥有数百万甚至数十亿参数的深度学习模型。这些模型通过训练海量数据集来捕捉和学习复杂的模式和特征。
2. Transformer架构的核心机制
Transformer架构,最初由Vaswani等人在2017年提出,以其自注意力(self-attention)机制而闻名。这种机制允许模型在处理序列数据时,无需考虑输入序列中元素的顺序,直接计算任意两个元素之间的关系,从而有效处理长距离依赖问题。
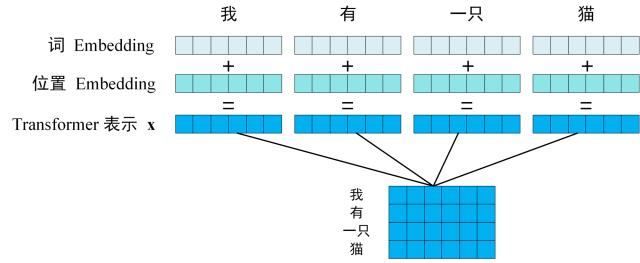

2.1 位置编码
在Transformer中,位置编码(Positional Encoding)是关键,它允许模型理解单词在序列中的位置。位置编码可以通过以下公式计算得到:
\[PE(pos, 2i) = \sin(pos / 10000^{2i/d})\] \[PE(pos, 2i+1) = \cos(pos / 10000^{2i/d})\] 其中,\(pos\) 表示单词在句子中的位置,\(d\) 表示PE的维度(与词Embedding一样),\(2i\) 表示偶数的维度,\(2i+1\) 表示奇数维度。2.2 自注意力机制
自注意力机制通过计算序列中每个元素对其他所有元素的注意力权重,来捕捉元素间的复杂关系。注意力分布后,对输入向量加权平均可以得到attention值:
\[\operatorname{att}(X, \boldsymbol{q}) = \sum_{n=1}^N \alpha_n x_n = \mathbb{E}_{z \sim p(z|X, \boldsymbol{q})}[x_z].\]2.3 编码器-解码器架构
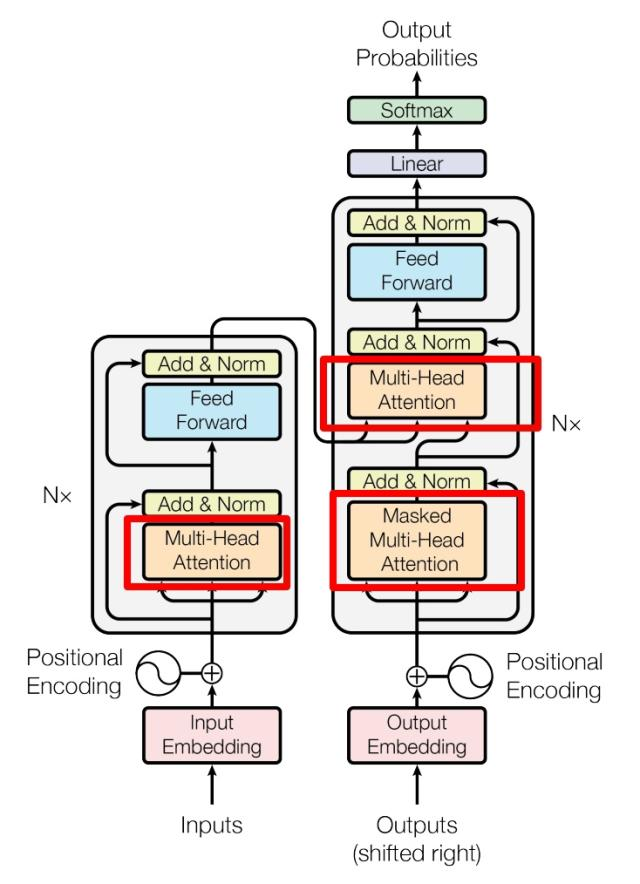
Transformer模型通常由编码器(Encoder)和解码器(Decoder)两部分组成。编码器负责将输入序列编码成连续的表示,而解码器则根据编码的表示生成输出序列。每个编码块的组成可以用这个等式表示:
\[ \text{Encoder Block Output} = \text{LayerNorm}(X + \text{MultiHeadAttention}(X) + \text{FeedForward}(X)). \]3. 大模型训练的挑战与策略
训练大模型需要巨大的计算资源和大量的数据。为了提高训练效率和稳定性,研究者们采用了分布式训练和混合精度训练等策略。分布式训练通过在多个GPU或TPU上并行处理数据,加速模型训练过程。混合精度训练则通过结合单精度和半精度计算,减少内存占用并提高计算速度。
4. 大模型的广泛应用
大模型因其强大的学习能力,在自然语言处理(NLP)、计算机视觉、语音识别等多个领域都有广泛的应用。例如,在NLP领域,大模型能够进行语言翻译、文本摘要、情感分析等任务;在计算机视觉领域,它们能够执行图像识别、目标检测等任务;在语音识别领域,大模型能够实现语音到文本的转换。
5. 大模型面临的挑战
尽管大模型在性能上取得了显著的进展,但它们也面临着一系列挑战。这些挑战包括模型的可解释性、数据偏见和公平性问题,以及对环境的影响。为了解决这些问题,研究者们正在探索新的模型架构、训练方法,并加强对伦理和社会责任的考量。
6. 大模型的未来趋势
随着技术的不断进步,大模型将继续发展和进化。我们期待看到新的架构和训练方法的出现,以及对大模型伦理和社会责任的更深入探讨。此外,随着硬件技术的发展,如更高效的GPU和TPU,大模型的训练和部署将变得更加便捷和高效。